

How do you prepare input text for training LLMs?#
At the heart of it, LLMs are just neural network. So you need data. The parameters of the LLM are optimized and then we have some output. The question is, the data that comes in as the input, what from should it take? How should we prepare the input text?
We have a huge number of documents which the LLM is trained on which we have seen in previous sessions. The LLM is usually trained on billions of documents. But do we feed the document directly as input text? Do we feed the sentences of the document as the input text?
No. It turns out that we have to tokenize the document and then feed individual tokens. There is one more step after this which is called Vector Embedding. In this session, we will only be looking at tokenization.
The process of tokenization can be broadly be broken down into 3 steps:
Step 1: Splitting text into individual word and sub-word tokens
Step 2: Convert tokens into token IDs
Step 3: Encode token IDs into vector representations
Note: Step 3 comes under Vector Embeddings so we will check out Step 1 & 2.
Visual of how input is fed to LLM#

Step 1 & 2: Tokenizing Text and Converting Tokens into Token IDs#
For the existing vocabulary, we are going to add two more tokens: unk which means unknown and also token called endoftext, along with corresponding token ID. These two are the last two tokens in the vocabulary so the token IDs corresponding to these two tokens will be the largest.
What actually happens is, when a new word is encountered in a sentence, for example, consider a sentence “The fox chased the dog quickly”, and “quickly” is not available in vocabulary, so when tokenized, the word “quickly” will have the token ID 783 which is the token ID of unk.
What about the token <|endoftext|>?<|endoftext|> is a bit different.
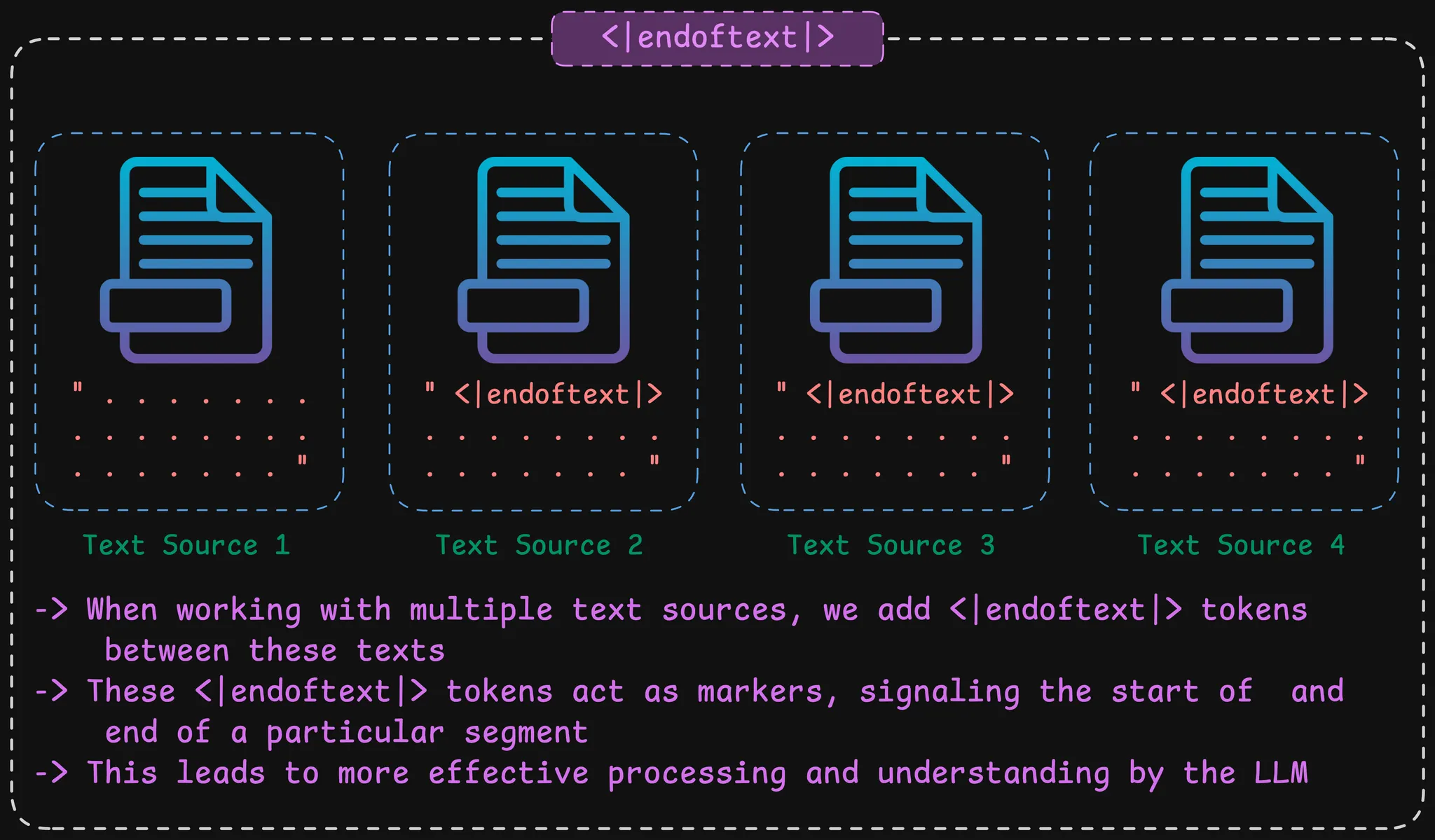
Assume Text Source 1 comes from one book, Text Source 2 comes from news article, Text Source 3 comes from encyclopedia and Text Source 4 which comes from interview. Assume these are our training sets. Usually all these are not collected into one giant document or all of these sentences are not stacked up together.
Usually, after the initial text has been fed as an input, we have the <|endoftext|> token, which means that the first text has ended and now the second text has started. After the second text has ended, then again the <|endoftext|> is added and third text starts and so on.
- When working with multiple text sources, we add
<|endoftext|>token between the texts. - These
<|endoftext|>tokens act as markers, signaling the start or end of a particular segment. - This leads to more effective processing and understanding by the LLM.
When GPT was trained the
<|endoftext|> tokens were used between different text sources.Code for this session#
You can find the code implementation for this session here ch-01/pre-process.ipynb