In the stages of building LLMs, there are basically two stages which we are going to look at.
Creating an LLM = Pre-training (1st stage) + Fine-tuning (2nd stage)
We will be building our own LLM so we are going to be looking at both of these stages.
It means training on a large and diverse dataset. What does this mean? How can this LLM interact so effectively with me so accurately and correctly?
The way the LLMs do that is because they are trained on a huge and diverse set of data. GPT-3 which was the precursor of GPT-4 had 175 billion parameters and it was trained on huge corpus of data.
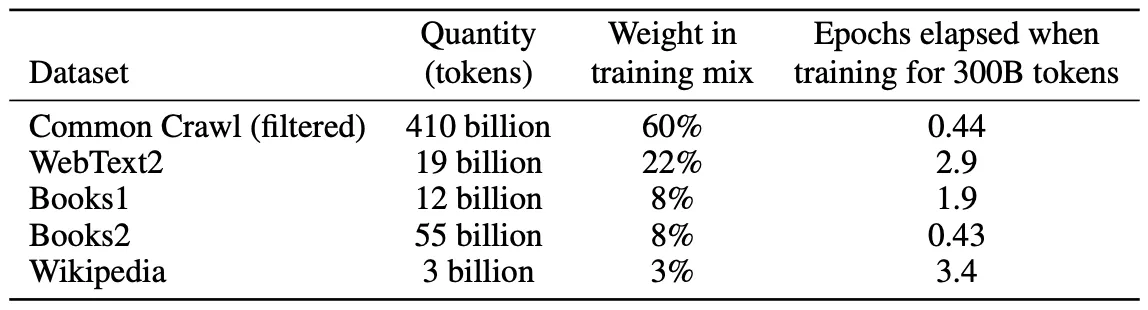
The places from where they got the data to train is given in the paper as below:
Just for the sake of simplicity think one token = one word. Look at the amount of data the GPT-3 was trained on. Overall GPT-3 was trained on over ~300 billion tokens.
Initially when large language models were actually trained on this data, they were trained for word completion task. Meaning, if the sentence was "The lion is in the __________", the LLM would be able to fill the blank as forest. What really surprised people was that even if you train the LLM for this simple task it turns out that it can do a wide range of other tasks as well.
This means that even though you just train the LLM for predicting the next word, it turns out that LLM can also do variety of other things like translation, answering MCQ, summarizing text, sentient detection etc. And we did not specifically train the LLM on any of these tasks. Yet it can do all these tasks so well. That is why LLMs have become so much popular than NLP. Because in NLP, let’s say you want to make a language translator, you need to train it separately. If you want to build quiz answer chatbot, you need to train it separately. If you want to build an AI which detects emotion from the text, you again need to train a separate NLP model.
But with pre-training LLMs, you get one model which can do all of these tasks without ever being trained for these tasks.
Then why is it that we need fine-tuning?
Let’s say you are a manager of an Airline company and you want to develop a chatbot so that users can interact with chatbot and the chatbot responds. Now the response which you want is very specific to your company and not a generic response which is collected from all the places in the internet. Or if you are a big tech education company and want to provide a feature for teachers to use a high quality tool based on LLM to generate MCQs, then you should not just rely on pre-trained model but fine-tune them as well.
Main purposes of Fine tuning are it is basically a refinement by pre-training on a much narrower dataset, specific to a particular task or domain.
SK Telecom (South Korea) telecommunications operator example SK Telecom collaborated with OpenAI to fine-tune GPT-4 for telecom customer-service conversations in Korean. Source Results reported:
+35% improvement in conversation-summarization quality
+33% improvement in intent-recognition accuracy
Customer satisfaction scores rose from ~3.6 to ~4.5 (out of 5) comparing fine-tuned model vs base GPT-4.
Why it’s notable: Demonstrates fine-tuning in a non-English, domain-specific environment (telecom), showing performance gains in real customer-service workflows. More such notable examples: ChatGPT - Finetuning GPT Examples
Essentially you will see when you go to production level or when you think of startups or industries, you will definitely need fine-tuning. Directly using pre-trained models is good for students because it satisfies their purposes, but fine-tuning is required as you build more advanced applications.
The first block is the data on which models are trained on. The data is either internet text, books, media, research articles etc. We need huge amount of data and you need to train the large language model on this dataset. This data can include billions or even trillions of words.
One point to raise here is the computational cost for training the LLM, which is also the second step in the schematic diagram. It is not possible for students or even for anyone who do not have access to powerful GPUs to do this.
The third step in schematic is fine-tuning. Meaning after fine-tuning, you can get specific applications. For example, you can build your own personal assistant or translation or classification bot etc. If you are startup or have an industry looking for these specific applications using your own data, you will fine tune the pre-trained LLM on the label dataset.
One thing to note is for pre-training it is trained by doing auto-regressively self-supervised. But for fine-tuning we will have a labeled dataset.
Train on a large corpus of text data (raw text). Raw Text = regular text without any labeling information
First training stage of LLM is also called pre-training. Creating an initial pre-trained LLM (base/foundational model). Example: GPT-3 model is a pre-trained model which is capable of text completion.
After obtaining the pre-trained LLM, we can further train LLM on labeled data which is called fine-tuning.
There are 2 popular categories of fine-tuning.
Instruction fine-tuning: Labeled datasets consists of instruction-answer pairs. Example, text translation, airline customer support.
Fine-tuning for classification tasks: Labeled dataset consists of text and associated labels. Example, emails → spam vs no-spam.