

Basic Intro to Transformers#
We will not go into the math or code of transformers but rather but we are just going to introduce the flavor of this concept. We will answer questions like what does it actually mean? What it did for large language models? What is the history of transformers in the context of GPT? Is there any similarity or differences between LLMs and Transformers?
The secret sauce behind LLMs and the secret sauce behind why LLMs are so popular is this word called as Transformer.
The Genesis of Transformers: The “Attention Is All You Need” Paper#
Most modern LLMs rely on the transformer architecture → Deep Neural Network architecture introduced in 2017 paper “Attention is all you need”
Research Paper Link
This paper has more than 200K citations in just 7 years because this paper led to so many breakthroughs which happened later. The GPT architecture which is the foundational stone or foundational building block of ChatGPT, origination from this paper. The GPT architecture is not exactly the same as the Transformer architecture proposed in this paper, but it is heavily based on that.
Architecture of the transformer provided in the paper:#
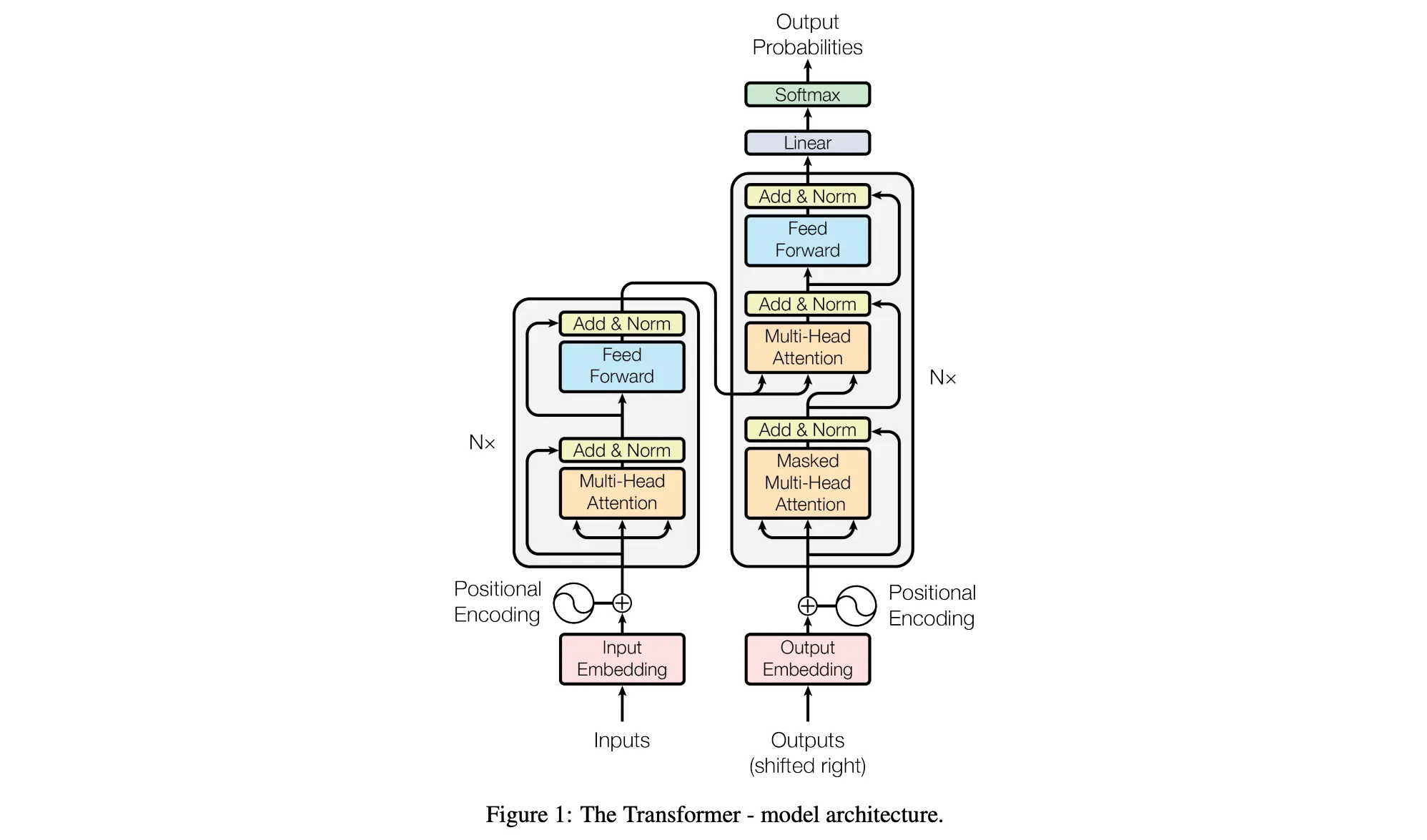
Essentially it is a neural network architecture and there are so many things to unpack and explain here. Every aspect of this architecture will need a separate study, it is that detailed. For now we will look at the overview of it.
When this paper was proposed, it was for translation tasks and text completion which is predominant role of GPT was not even in consideration here. They were mostly looking at English to French and English to German translation tasks. The Transformer mechanism they proposed led to big advancement in these tasks.
Later it was discovered that using an architecture derived from this Transformer architecture we can do so many things.
Deconstructing the Simplified Transformer Architecture#
The above schematic transformer architecture is very detailed and here is the tone downed version of it inspired and borrowed from the book Building LLMs from Scratch by Sebastian Raschka.
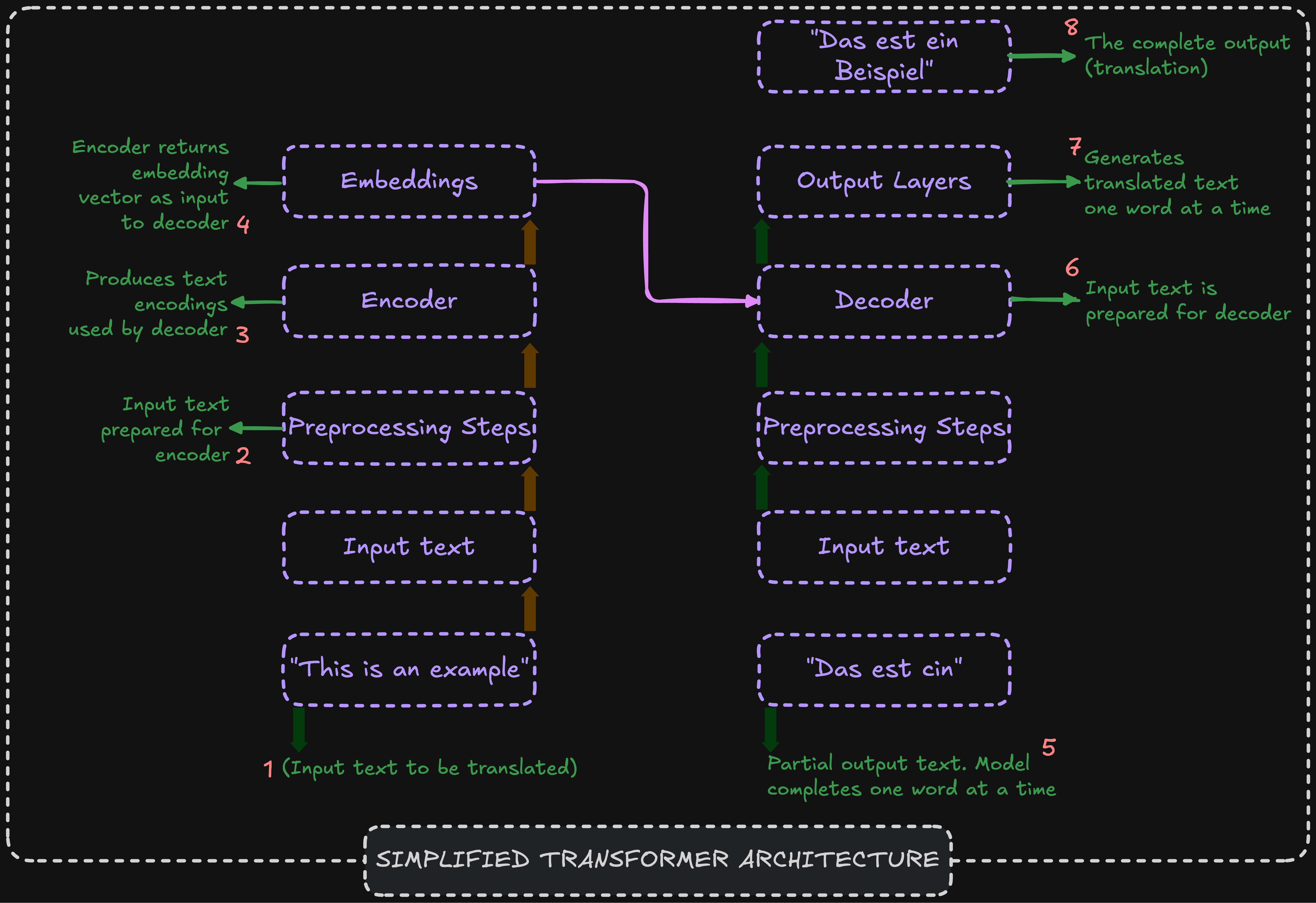
Understanding these 8 steps = understanding the intuition behind Transformers Architecture
Step 1: Input text to be translated which is in English. The transformer is designed so that at the end of 8 steps it will convert it into German.
Step 2: Input text is taken and pre-processed. These input text undergo a process called Tokenization. Let’s say the input data is in the form of documents and documents have sentences. The entire sentence cannot be fed into the model. The sentence need to be broken down into simpler words or tokens. This process is called Tokenization. Below is the simple schematic of tokenization:
Step 3: Encoder is one of the most important building blocks of the Transformer architecture. What encoder does is that, the input text which is pre-processed, let’s say tokens, are passed to the encoder and what actually happens in the encoder is it implements a process called as Vector Embeddings.
Step 4: Up till now we have seen that every sentence is broken down individual words and those words are converted into numerical IDs. But the main problem is that we need to encode the semantic meaning between the words also.
If you take the word dog and puppy, with this method of tokenization random IDs will be assigned to dog and puppy but we need to encode this information somewhere that dog and puppy are actually related to each other. So, can we somehow represent the tokens in a way which captures the semantic meaning between the words? And that process is called as Vector Embeddings.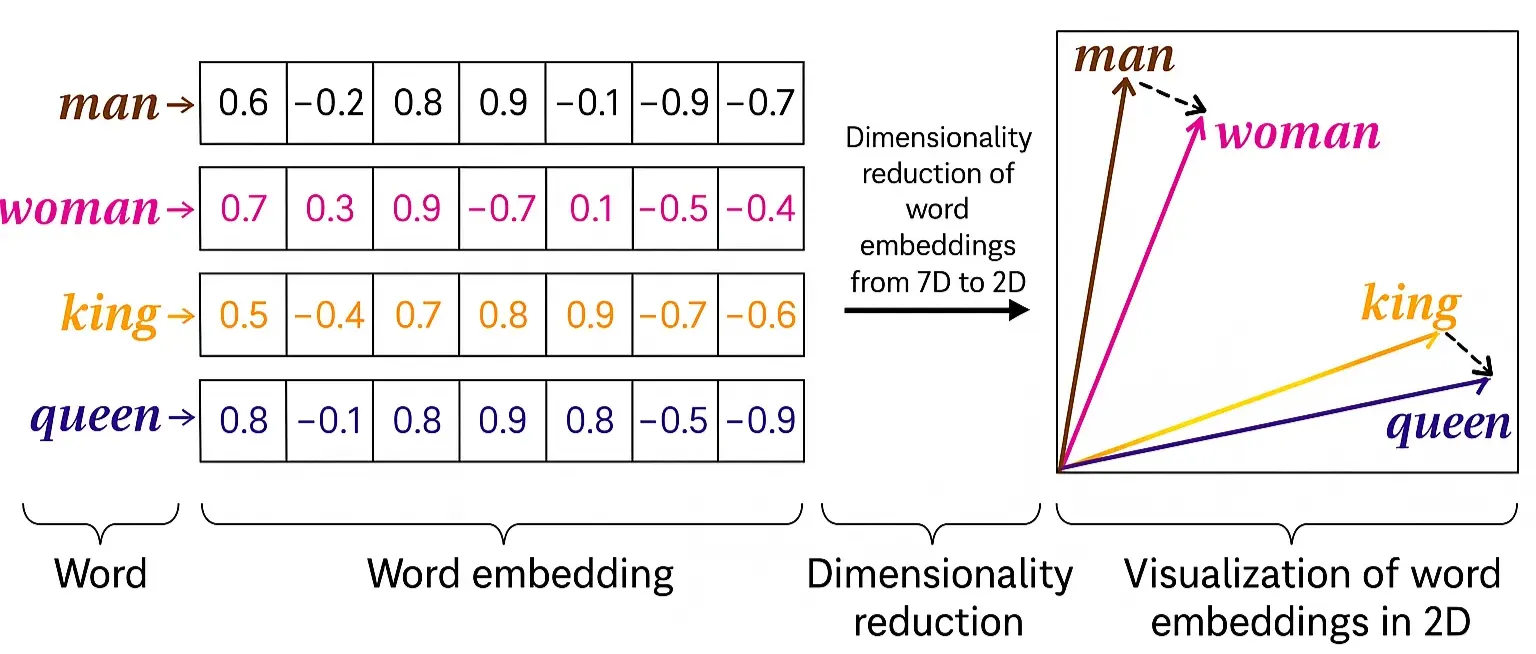
What is done usually in Vector Embeddings is that, words are taken and they are converted into vectorized representations. This is a difficult task. We cannot randomly put vectors. Apple-Banana have to be closer to each others. All fruits need to be closer to each other than, let’s say, Banana and Golf. There is usually a detailed procedure for this and neural networks are trained even for this step → Vector Embedding step.
Step 5: This is the German translation which our model will be doing. The model completes one word at a time. “This is an example” is the input and up till now let’s say the model has translated this to be “Das est ein”. This is not complete translation because the translation of the word “example” is not yet included. This can be called as the partial output text. And these already translated words will be available to the model when it is trying to process next word which is “example”. Even the existing already translated words, that is, “Das est ein” is converted into the tokens by tokenization as a pre-processing step and is fed to the Decoder.
Step 6: The job of the Decoder is to do the final translation. Remember, along with “Das est ein” which is the partial translated sentence, the Decoder also receives the Vector Embeddings from the left side of schematic diagram above. It has received embeddings and it has received the partial text and now the task of the Decoder is basically to predict what the next word is going to be based on this information.
Step 7: Then we go to the output layer. The decoder generates the translated text one word at a time. In the example, it predicts “Beispiel” (the German word for “example”). This process is trained like a standard neural network, using a loss function to improve prediction accuracy over time.
Step 8: The process repeats until the final, fully translated output sentence is produced sequentially.
The Core Components and the Self-Attention Mechanism#
The two primary building blocks of the Transformer—the encoder and decoder—and introduces the pivotal concept of self-attention, which is the central innovation of the architecture.
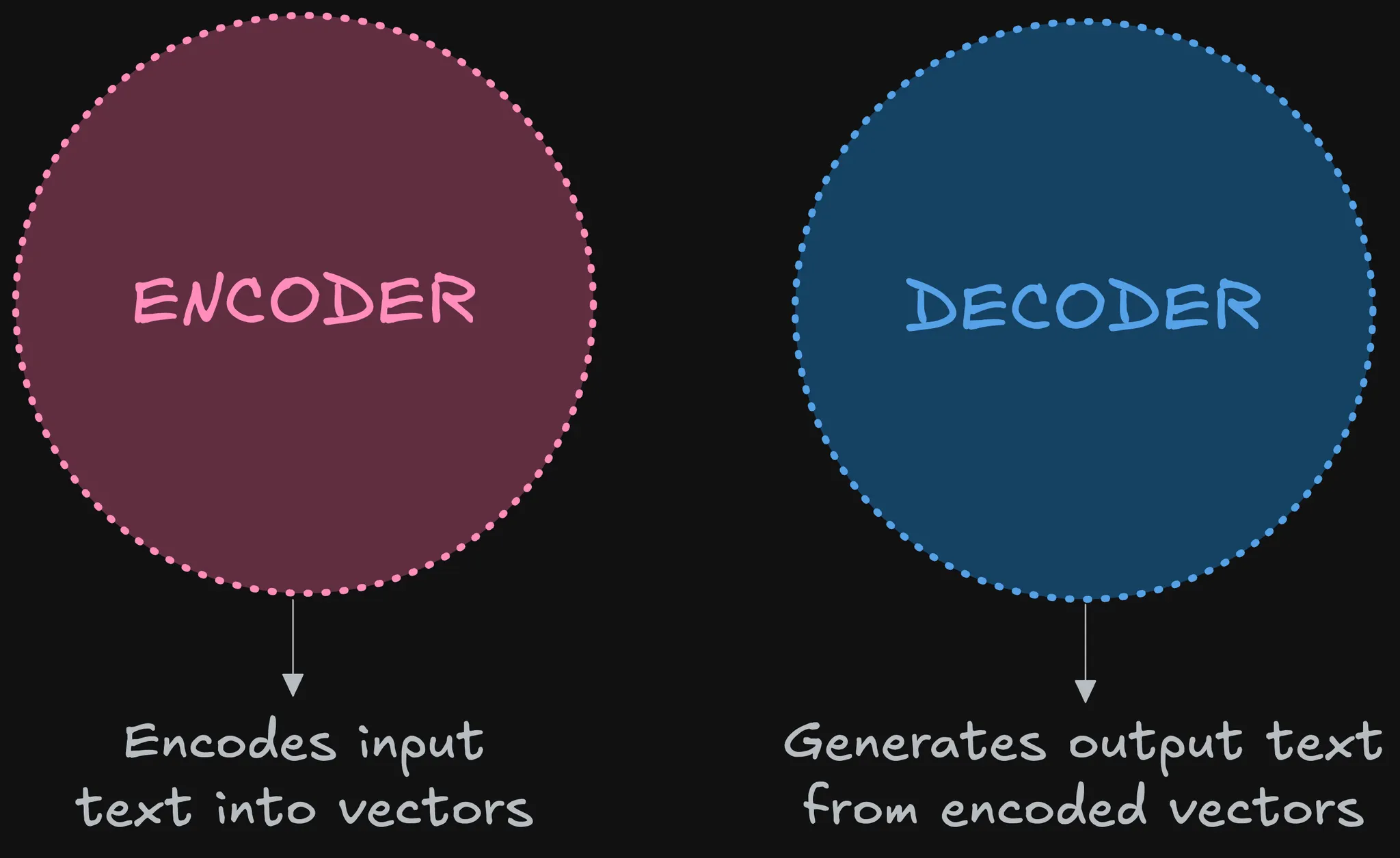
Encoder and Decoder Blocks#
Encoder: Its main purpose is to process the input text and convert it into meaningful vector embeddings that capture the semantic context of the source language.
Decoder: Its main purpose is to take the encoder’s embedding vectors and the partial output text to generate the final output sequence, one token at a time.
The Self-Attention Mechanism#
Self-attention is the central innovation of the Transformer, as highlighted by the title of the original paper, “Attention is All You Need.”
Its function is to allow the model to weigh the importance of different words or tokens relative to each other, regardless of their distance within the text.
“Harry Potter rides with Hagrid. He buys an owl and a wand. Harry Potter is standing in platform nine and three quarters”.
Here as a human we can understand and remember the context of what we read in previous sentence or previous page. What about models? Self-attention enables the model to capture long-range dependencies. To understand the current sentence, the model can “pay attention” to important words from previous sentences, maintaining context to make accurate predictions.
This is achieved by calculating an attention score for each word in relation to all other words in the input.
If you see the original transformer architecture (shown above) there are many attention blocks like Multi-Head Attention or Masked Multi-Head Attention. These make sure you capture long-range dependencies in the sentences.
This powerful mechanism became the foundational element that later architectures like BERT and GPT would modify for more specialized tasks.
Architectural Evolution: BERT vs. GPT#
The original Transformer architecture inspired later, specialized models. Let’s analyze and compare two of the most significant variations: BERT and GPT, highlighting their distinct designs and use cases.
Defining BERT and GPT#
BERT: Bidirectional Encoder Representations from Transformers.
GPT: Generative Pre-trained Transformers.
Comparative Analysis#
| Feature | BERT | GPT |
|---|---|---|
| Primary Task | Predicts masked or hidden words within a sentence. | Generates the next word in a sequence. |
| Directionality | Bidirectional: Looks at context from both left and right. | Unidirectional (Left-to-Right): Uses past context to predict the future. |
| Core Architecture | Uses only the Encoder part of the Transformer. | Uses only the Decoder part of the Transformer. |
| Key Strength | Excellent for understanding nuance and context (e.g., distinguishing word meanings), making it strong for sentiment analysis. | Excellent for text generation, completing sentences, and creative writing tasks. |
Clarifying the Taxonomy: Transformers vs. LLMs#
It is crucial to use AI terminology accurately. This section deconstructs the common misconception that Transformer and LLM are interchangeable terms, based on the speaker’s detailed clarification.
Not all Transformers are LLMs: The Transformer architecture is also applied to other domains, most notably computer vision. The speaker gives the example of Vision Transformers (ViT), which are used for tasks like image recognition, pothole detection on roads, and medical tumor classification.
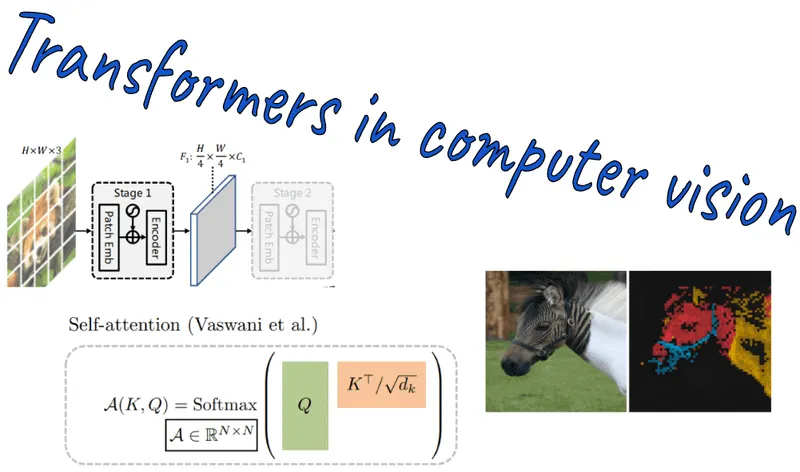
Read: https://viso.ai/deep-learning/vision-transformer-vit/ Not all LLMs are Transformers: Language models existed long before the 2017 Transformer paper. The speaker names older architectures, including Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, which can also perform text completion and other language tasks.
Source: StatQuest YouTube Channel - Transformers Evolution