

Engineering Breakthrough: Scaling LLM Development Down to $100 with Andrej Karpathy’s NanoChat#
Introduction#
In an era defined by massive capital expenditure on Large Language Models (LLMs)—often costing tens or hundreds of millions of US Dollars—efficiency and accessibility are crucial priorities for accelerating AI research. Andrej Karpathy’s nanochat project represents a significant engineering achievement, proving that a full-stack, production-quality LLM pipeline can be built and pre-trained for the remarkably low cost of $100.
Nanochat is explicitly billed as “The best ChatGPT that $100 can buy”. It is not merely a theoretical exercise; it is a clean, minimal, hackable, and dependency-lite codebase that runs the entire end-to-end pipeline: tokenization, pretraining, finetuning, evaluation, inference, and web serving over a simple user interface. This project is designed to become the capstone project for the upcoming course LLM101n, developed by Eureka Labs, emphasizing its pedagogical value.
Architectural Philosophy: Minimalism Meets Performance#
The core philosophy of nanochat is centered on maximizing accessibility and research velocity, which often means prioritizing clarity and robustness over complex, proprietary kernels, though efficiency tricks are integrated where they are most impactful.
Core Model Specifications#
The $100 tier of nanochat utilizes a small, efficient transformer architecture:
- Number of Layers (Depth): 12.
- Dimension: 768.
- Sequence Length: 2048.
The model structure follows the standard transformer design: an input embedding layer, multiple transformer blocks, and a final output head. The output head, which maps the token embedding back to the vocabulary size (e.g., 50,000 vocab size), can be surprisingly massive in smaller models, sometimes constituting up to a third of the model’s total memory.
NanoChat Architecture Overview#
Strategic Architectural Choices#
Rotary Positional Embeddings (RoPE): Karpathy implements RoPE from scratch, noting its beautiful and simple implementation. RoPE is applied specifically to the query and key vectors. For efficiency, the cosine and sine values required for the rotation matrices are pre-computed and stored in GPU memory, as they do not depend on the neural network weights. While highly optimized kernel versions of RoPE exist (e.g., from
torch AO), the raw PyTorch implementation in nanochat is ideal for learning and understanding the mechanism.Multi-Query Attention (MQA): Nanochat employs Multi-Query Attention (MQA), specifically utilizing the
repeat KVfunction. MQA significantly improves inference speed by grouping tokens and sharing the same key (K) and value (V) vectors across the group, eliminating redundant computations, while each token maintains a unique query (Q) vector.Multi-Layer Perceptron (MLP) and Activation:
- The model uses a standard Feed-Forward Network (FFN) instead of a Mixture of Experts (MoE). MoE, while useful for inference, adds significant engineering complexity. The simpler MLP is preferred because findings derived from MLP research are often applicable to MoE systems.
- The activation function is GELU squared (referred to as
rel square), an optimization observed in training speedruns to achieve faster and better training performance.
The MuON Optimizer: A Theoretical Advantage#
One of the most advanced components of the nanochat implementation is its sophisticated optimization strategy, which utilizes a split-optimizer approach:
- AdamW is used for optimizing the embeddings and the Language Model (LM) head.
- MuON (Matrix Update via OrthoNormal) is used for optimizing 2D weight matrices.
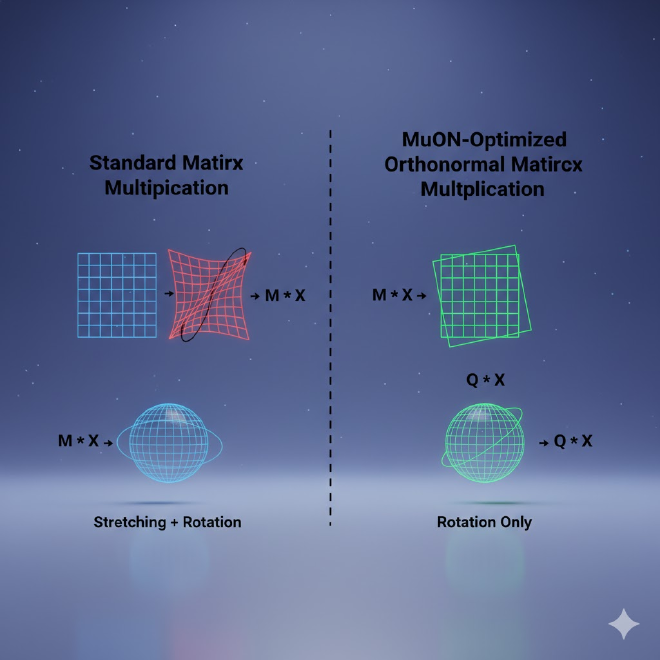
MuON is based on advanced theoretical research. It aims to ensure that weight matrices remain orthonormal throughout training. Standard matrix multiplication acts as a linear transformation that can rotate, stretch, or squish vectors. By enforcing orthonormality (where rows or columns are orthogonal), MuON ensures that the multiplication operation only rotates the vectors, preventing them from being stretched or squished. This is achieved through techniques like Newton-Schulz iterations. The theoretical benefit is that eliminating this stretching behavior allows the model to learn faster and with less data.
MuON vs. Standard Matrix Transformation#
Execution and Deployment: The $100 Speedrun#
The practical deployment of nanochat is designed to be fully reproducible, with the entire pipeline packaged into a single script: speedrun.sh.
Quick Start and Cost#
The fastest way to experience the system is to run speedrun.sh.
- Compute Required: A single 8xH100 node.
- Runtime: Approximately 4 hours.
- Total Cost: Based on a $24/hr rate (e.g., from Lambda), the total cost is approximately $100.
- Capability: This $100 speedrun produces a 4e19 FLOPs capability model. Karpathy compares its conversational ability to “talking to a kindergartener” due to its simplicity, noting it can still write poems or explain phenomena like why the sky is blue.
Upon completion, the model can be served using python -m scripts.chat_web to provide a ChatGPT-like web UI for interaction.
Scaling and Performance#
While the $100 model is fully functional, it dramatically falls short of modern LLMs like GPT-5. The GitHub repository outlines potential scaling tiers for increased performance:
| Tier | Depth | Parameters (Approx) | Training Time (8xH100) | Cost (Approx) | Performance Notes |
|---|---|---|---|---|---|
| Speedrun | 12 | (Smaller) | 4 hours | $100 | Kindergartener-level (4e19 FLOPs) |
| Mid-Tier | 26 (d26) | (Larger) | ~12 hours | $300 | Slightly outperforms GPT-2 CORE score |
| High-Tier | (Not specified) | (Larger) | ~41.6 hours | $1000 | A conceptual larger scale |
| Example Model | 32 (d32) | 1.9 billion | 33 hours | ~$800 | Trained on 38B tokens; prone to mistakes and hallucination, like a child |
Evaluation and Hardware Flexibility#
Nanochat automatically generates a report.md file, providing a “report card” of the run, which includes essential evaluations and metrics such as CORE, ARC-Challenge, GSM8K, and MMLU scores.
The code is highly flexible and engineered to run on various compute environments:
- It runs well on 8xH100 nodes but can also run on 8xA100 nodes (albeit slower).
- It supports single-GPU operation by omitting
torchrun, though users must wait 8 times longer. - For GPUs with less than 80GB VRAM, the hyperparameter
--device_batch_sizemust be reduced (e.g., from 32 to 16, 8, etc.) to prevent Out-of-Memory (OOM) errors. - There is work in progress for CPU and MPS (Macbook) support, allowing users to tinker or train very tiny LLMs with patience.
Conclusion#
Nanochat stands as a powerful demonstration of focused engineering and architectural clarity. By leveraging advanced components like the MuON optimizer and MQA, and by adhering to a minimal, hackable code base, Andrej Karpathy has provided the AI community with an accessible, high-quality, end-to-end LLM blueprint achievable for the cost of a few hours of cloud compute time. This work offers crucial lessons for engineers seeking to optimize both efficiency and cognitive complexity in the next generation of foundational models.
References#
- Karpathy, A. (2025). nanochat: The best ChatGPT that $100 can buy. GitHub. https://github.com/karpathy/nanochat